签到天数: 196 天
[LV.7]常住居民III
771
6816
7536
管理员
非物质文化遗产社会摇传承人
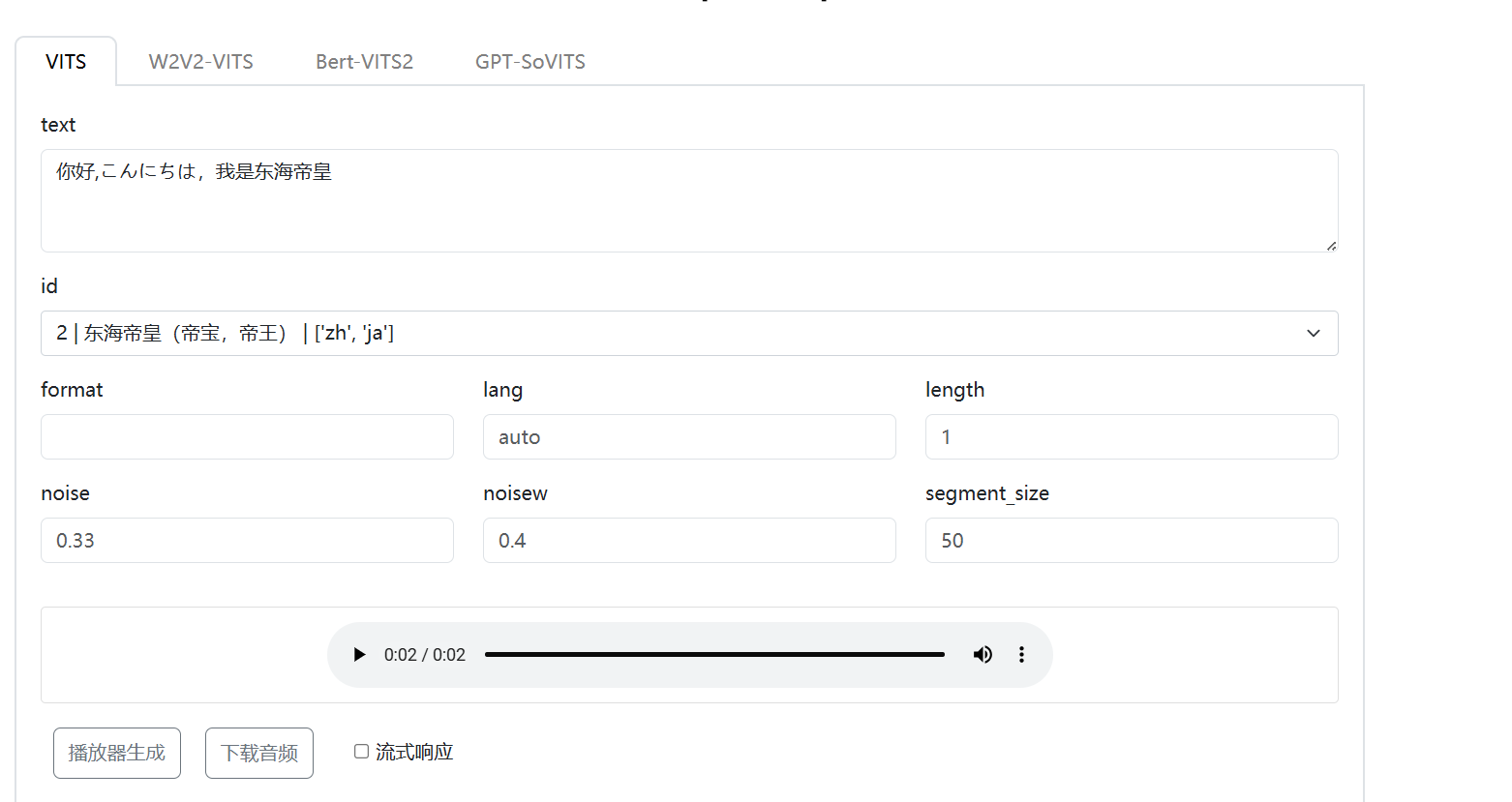
一开始是使用的传统tts发现合成效果太生硬了...兜兜转转前阵子从软件提取出来一个pth文件,效果很好但是没搞懂格式,今天发现是vits的,于是尝试配置一下由于vits项目过老...我没配置成功,所以最后在尝试vits-simple-api成功的虚拟环境部署一定要记着安装aconda输入git clone https://github.com/Artrajz/vits-simple-api.gitpip install -r requirements.txtpython app.py然后到data/model,创建一个新的文件夹放入config.json和pth文件如果没反应就去管理员面板看地址http://127.0.0.1:23456/admin/login?next=%2Fadmin%2F密码在项目的config.yaml找admin配置项下面有账号和密码如果模型没加载出来多半不兼容配置成功之后是这样然后拖入自己的模型,利用api访问就可以生成tts语音了
当然也可以自己训练模型,这部分我还没搞明白QAQ
使用道具 举报
签到天数: 226 天
318
5322
4890
该用户从未签到
0
49
31
助理工程师
本版积分规则 发表回复
通过论坛认证的开发者
油中两岁啦~
这个荣誉的勋章是为那些为脚本猫/油猴中文网生态做出贡献的会员而设。无论是编写代码、完善文档,还是发表教程,他们都是我们生态的重要建设者。 您的每一行代码,每一段文档,都是我们社区生态的重要一砖一瓦。您的贡献,不仅促进了技术的发展,也为其他成员提供了学习和成长的平台。您是我们社区的灵魂,是我们前进的动力。感谢您的努力和付出,让我们共同创造一个更美好的脚本猫和油猴中文网。
论坛管理员
2023年中秋纪念章
油中三岁啦~登录解谜网站即可获得https://puzzle.ggnb.top/
https://puzzle.ggnb.top/ 解谜通过20关获得











 置顶卡
置顶卡 沉默卡
沉默卡 照妖镜
照妖镜



