突然想到以前上学的时候小米课程表还在正常维护
当时官方提供了一个青果课程的文字识别
觉得特别厉害
慕然回首,小米课程表已经成为了一个废弃项目
就尝试着从头实现一次青果课程表的提取作为纪念吧
但是不确定会不会成功
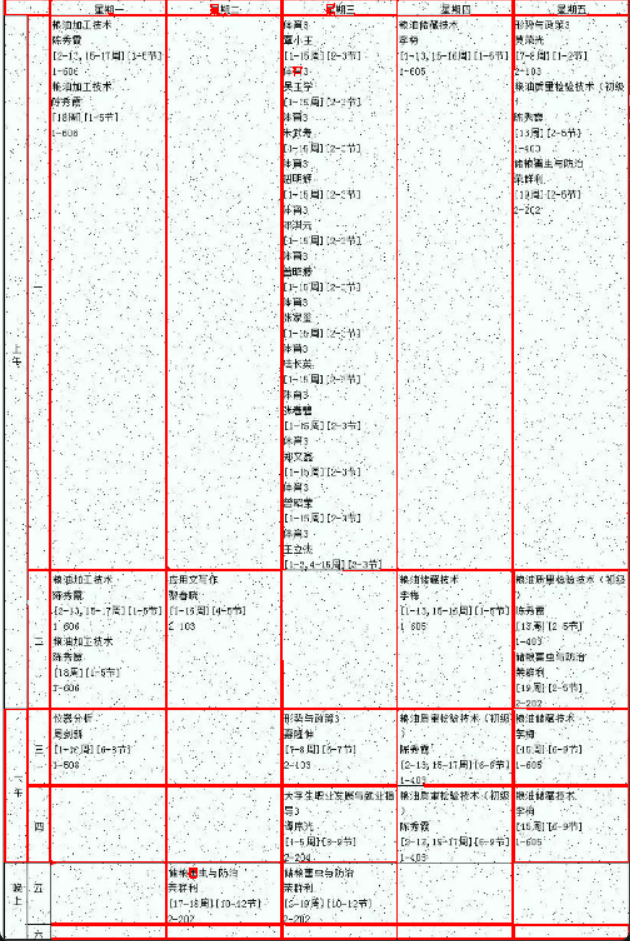
原图
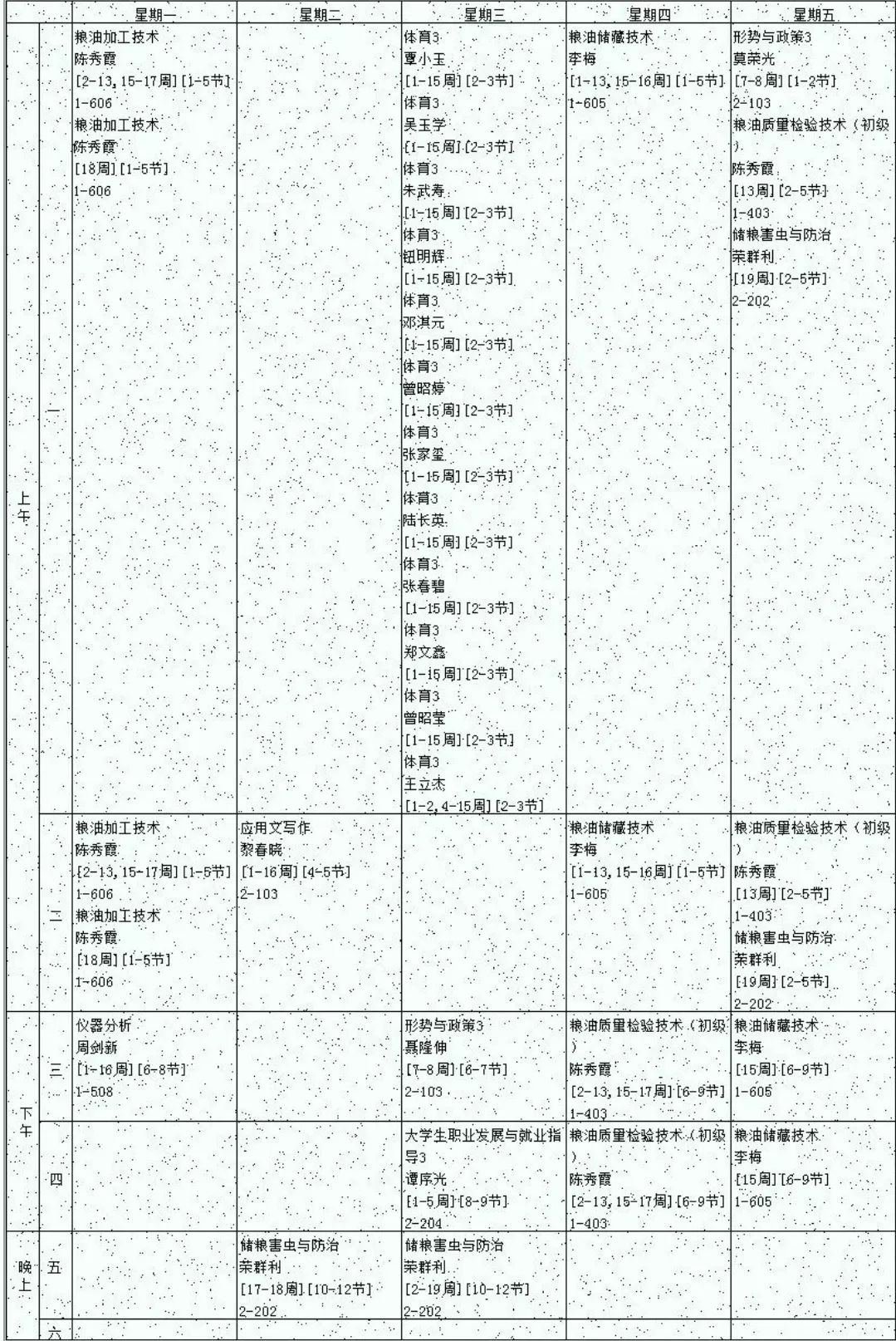
胡椒噪点的处理
一开始尝试二值化后用中值滤波发现文字也会被模糊掉
经过多种的滤波尝试
最后发现fastNlMeansDenoising(非局部平均去噪)的效果不错
import cv2
import numpy as np
originImage = cv2.imread("test.png")
image = cv2.cvtColor(originImage, cv2.COLOR_BGR2GRAY)
denoised_image = cv2.fastNlMeansDenoising(image, None, 30, 7, 21)
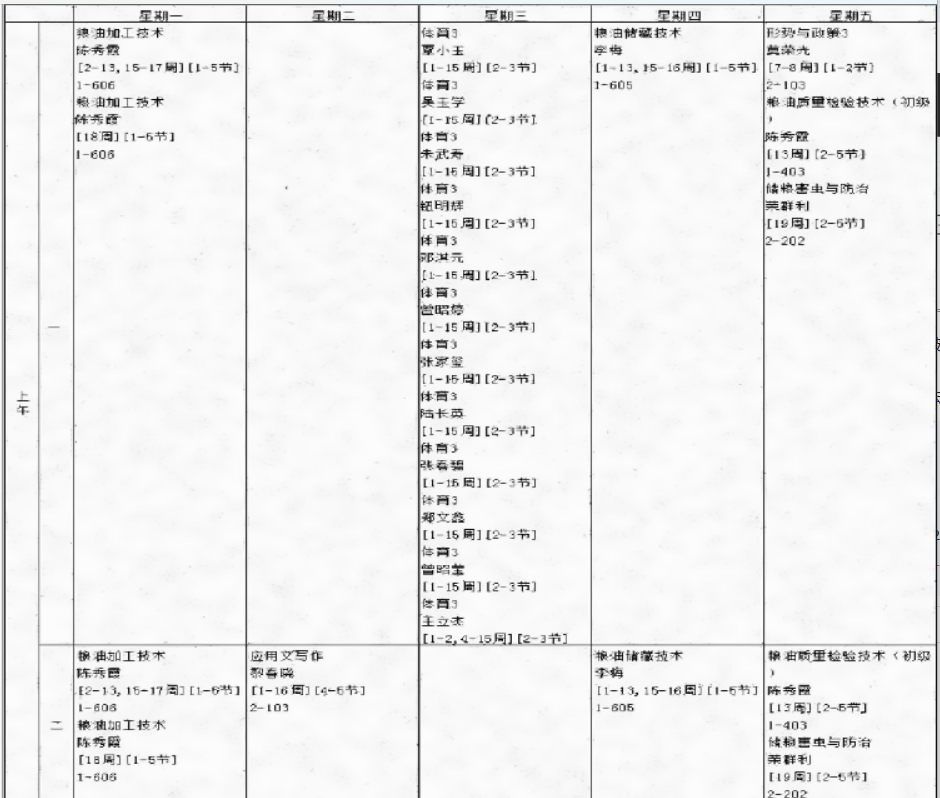
文字还算清晰,但是后边还是有胡椒噪点导致的斑斑点点,尝试用二值化去一下
ret, thresh = cv2.threshold(denoised_image, 220, 255, cv2.THRESH_TRUNC)
这个时候就基本干净了
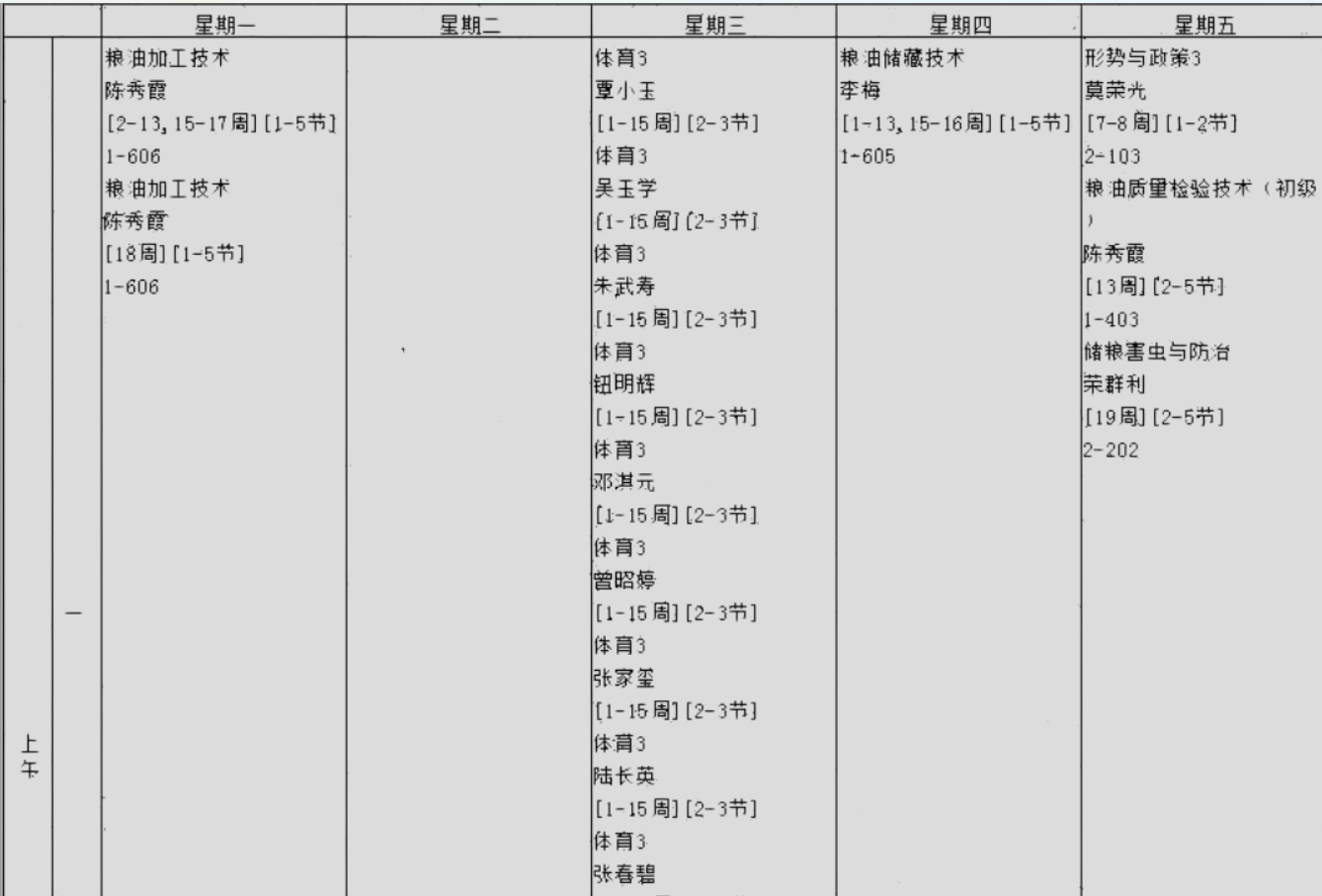
然后获取一下轮廓线做边缘监测
_, binary = cv2.threshold(thresh, 128, 255, cv2.THRESH_BINARY_INV)
edges = cv2.Canny(binary, 50, 150)
contours, _ = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
最后将所有的框画出来看你看
cv2.drawContours(originImage, contours, -1, (0,0, 255), 2)
看效果来说还可以,下一步画框对框内文字检测ocr
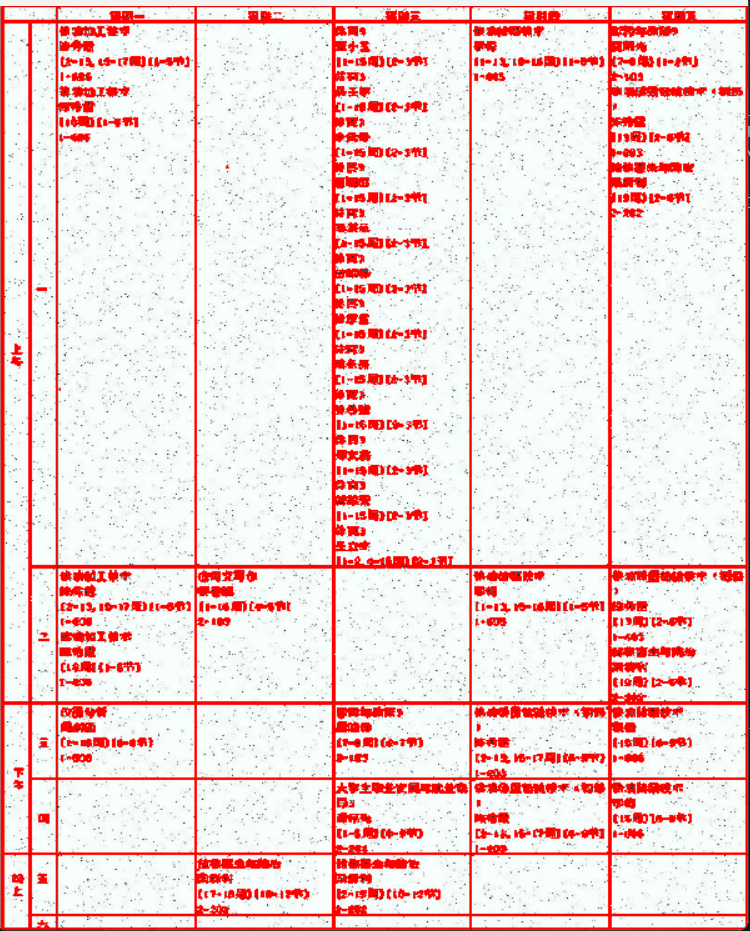
但是一旦尝试过滤就会发现有一部分框是没有被识别到的,这部分还没有解决
待续
loading....











 置顶卡
置顶卡 沉默卡
沉默卡 照妖镜
照妖镜



