本帖最后由 tfsn20 于 2022-12-2 10:56 编辑
本帖最后由 tfsn20 于 2022-12-2 10:55 编辑
本帖最后由 tfsn20 于 2022-12-1 23:24 编辑
感谢冷山哥哥提供的帮助和关键代码。🙂
demo地址sendHex,
打开微信官网使用。
发送一个16进制数据的post请求
let data = '19f10400a10000009d0104f10100a8025673537bdac747ed5a33862dc0b17c1b669ae7cdb1d99e341dcc9c4d89aae46386d0ac0000006f010000006a000f01000000630100093a80000000000048000c7fc14e6523d35471e93f64fd004814d6def5ffb908b002c7c0ee8ccc182e161ee06ccf701db0f74a20ac18a141651341830b9849dd653e85d79940c5036748b2cb8e0b85cb4997e628e0a100d1018d73af281b69e79c19f10400249804a8cdabe5d1842dd7bcaa4ed8ad0ac132eac2ed7a771bfa3ccbc404f456fd0c446cd417f1040195bb17859e5a4b3bc7a86c154159cc7c2804f681f03a5f3437b3d9d500bc1cef57b2ad7c4aef8a9c160632a5e1b9de76ffcbc8b393d719bd2e6418f65ff257684ab7ada6c02ac3d63074d2508bc7002e44417577a0ede9d4765ef9938b9eff95e1a5356bea737c20db98f612d392563cee95d3d6cc6a43d3942ca4d1d5cd5ec12a4e48ce905ba334ac28e8732024f37d6bbe623a9247323ca15889d9b9435ab21702ba54a246955870ed2f5b4e7b63d73badee8d74daf86926559fa1b4c82721305f389b8c60d38ae0f9d553002b04230590c2818add7deeed131a625f054677a6c55d8518c5dc15099add0341bcb8b25550e30ae4495df7fd22949586c5ccf8e6e56a66d608a0259010de0cbcfd76dc416a33778533eda25b856c0f7ef476d4285c60ab5a31a4ce6b6afacee5c520fadd32247fd17189731fa7c54fba4844bd2e62d5038085f99bb78fe915a4558cb64ea259dbbb3c2b15c4dacf2773d8abd59d4b893bd54b59965faaa4f944b224abd4ffbb54d43d19b534672488cc52de9a8420dee99628f90ea45a815d8e96e6ff7925f986c40e15f1040017e6e3ae6c8a48c97704dbfde7bd0dbc186af534e1bbc654';
直接转为数字不行,一是太大,而是大数要求必须是整数;
先创建一个具有data.length/2字节的Uint8Array
let buffer = new Uint8Array(data.length/2)
再两个两个的转为10进制放入buffer内
for (let i = 0, len = data.length; i < len; i = i + 2) {
buffer[i/2]=(parseInt(data[i] + data[i + 1], 16))
}
parseInt()函数可以把data[i]+data[i+1]这个字符串以16进制读取,返回10进制的数,所以放入buffer内的是10进制的数,parseInt的第一个参数还可以是数字
parseInt(10,2)
返回2,因为10以2进制读取就是10进制的2,然后请求的data需要把buffer转为blob读取data: new Blob([data]),具体如下
GM_xmlhttpRequest({
url: 'http://szextshort.weixin.qq.com/mmtls/3755b7e7',
method: 'POST',
data: new Blob([data]),
anonymous: anonymous,
responseType: 'blob',
headers: {
'sec-ch-ua-platform': '',
'dnt': '',
'sec-ch-ua': '',
'sec-ch-ua-mobile': '',
'Sec-Fetch-Site': '',
'Sec-Fetch-Mode': '',
'Sec-Fetch-Dest': '',
'User-Agent': 'MicroMessenger Client',
'Accept-Encoding': '',
'Content-Type': 'application/octet-stream',
'Accept': '*/*',
'Accept-Language': '',
//'Content-Length': '',
'Cache-Control': 'no-cache',
'Host': 'szextshort.weixin.qq.com',
'Upgrade': 'mmtls',
'Referer': '',
'origin': '',
'Cookie': ''
},
onload:function(xhr){resolve()}
}
buffer的内存数据刚好就是我们要传输的数据
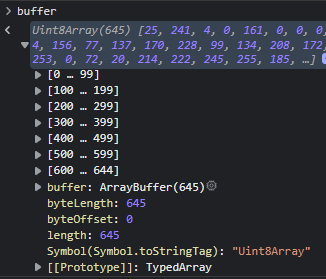
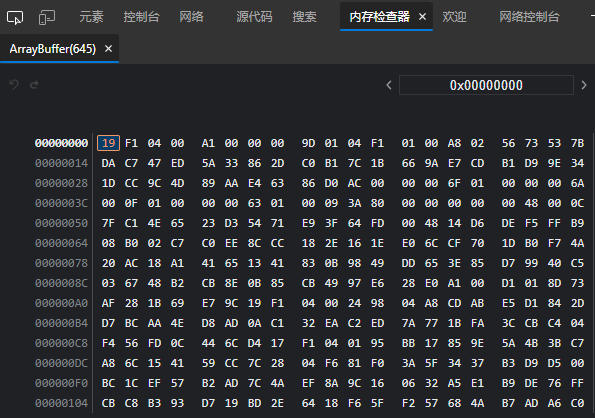 ,最后是接收数据,设置
,最后是接收数据,设置responseType: 'blob',,因为我们要接收一个流,
let blob = xhr.response;
var fr = new FileReader();
fr.readAsArrayBuffer(blob);
将blob以文件形式读取到fr中,在内存查看器就可以发现我们想要的数据了
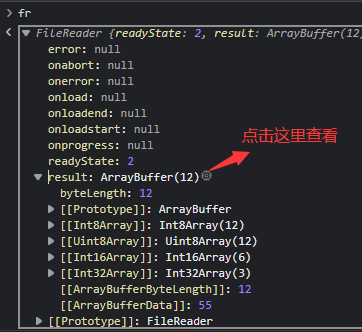
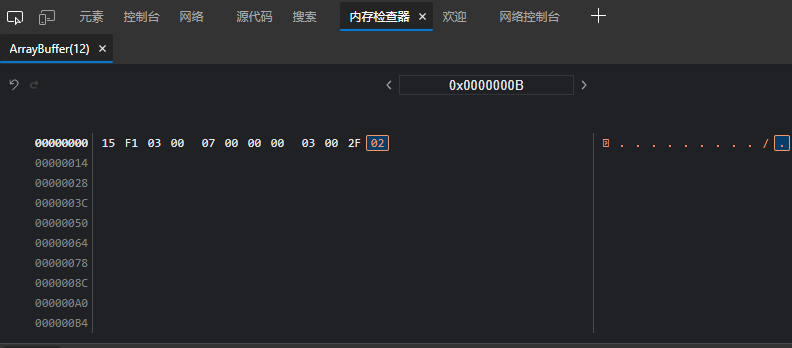
将onload里的代码改改就可以输出16进制字符串了
let blob = xhr.response;
var fr = new FileReader();
unsafeWindow.fr = fr;
fr.addEventListener("load", function (ev) {
var abb = ev.target.result;
var iAA = new Uint8Array(abb);
// console.log(iAA);
// console.info(fr);
console.log(unsafeWindow.iAA = iAA);
let t = '';
for (let i = 0, len = iAA.length; i < len; i++) {
t = t + iAA[i].toString(16);
}
console.log(t)
});
//把blob文件转化为arraybuffer;
fr.readAsArrayBuffer(blob);

为什么用Uint8array,Uint8Array代表8个比特,也就是一个字节,代表他每个内存单元存储一个字节,我们要发送的数据是645个字节,刚好645个坑,如果用Unit16Array,就是2个字节一个坑,这导致645个字节前644个占了322个坑,最后一个字节一个坑占不完,会填充0,导致数据不对。而且不知道为啥每两个字节都颠倒了顺序,如图
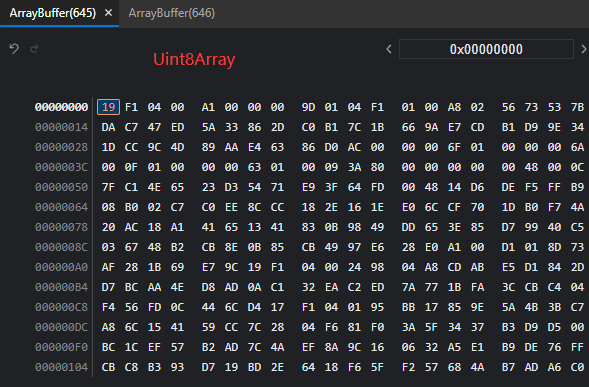
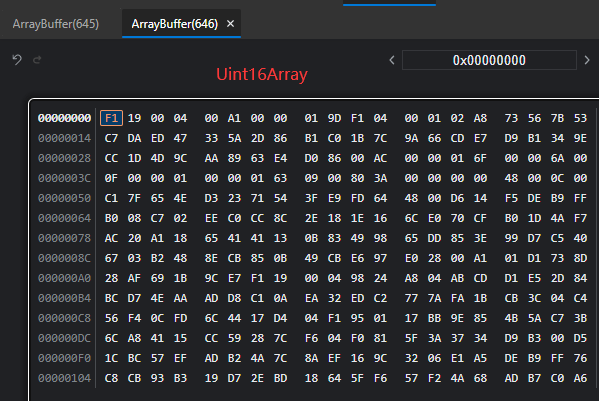
代码如下:
let data = '19f10400a10000009d0104f10100a8025673537bdac747ed5a33862dc0b17c1b669ae7cdb1d99e341dcc9c4d89aae46386d0ac0000006f010000006a000f01000000630100093a80000000000048000c7fc14e6523d35471e93f64fd004814d6def5ffb908b002c7c0ee8ccc182e161ee06ccf701db0f74a20ac18a141651341830b9849dd653e85d79940c5036748b2cb8e0b85cb4997e628e0a100d1018d73af281b69e79c19f10400249804a8cdabe5d1842dd7bcaa4ed8ad0ac132eac2ed7a771bfa3ccbc404f456fd0c446cd417f1040195bb17859e5a4b3bc7a86c154159cc7c2804f681f03a5f3437b3d9d500bc1cef57b2ad7c4aef8a9c160632a5e1b9de76ffcbc8b393d719bd2e6418f65ff257684ab7ada6c02ac3d63074d2508bc7002e44417577a0ede9d4765ef9938b9eff95e1a5356bea737c20db98f612d392563cee95d3d6cc6a43d3942ca4d1d5cd5ec12a4e48ce905ba334ac28e8732024f37d6bbe623a9247323ca15889d9b9435ab21702ba54a246955870ed2f5b4e7b63d73badee8d74daf86926559fa1b4c82721305f389b8c60d38ae0f9d553002b04230590c2818add7deeed131a625f054677a6c55d8518c5dc15099add0341bcb8b25550e30ae4495df7fd22949586c5ccf8e6e56a66d608a0259010de0cbcfd76dc416a33778533eda25b856c0f7ef476d4285c60ab5a31a4ce6b6afacee5c520fadd32247fd17189731fa7c54fba4844bd2e62d5038085f99bb78fe915a4558cb64ea259dbbb3c2b15c4dacf2773d8abd59d4b893bd54b59965faaa4f944b224abd4ffbb54d43d19b534672488cc52de9a8420dee99628f90ea45a815d8e96e6ff7925f986c40e15f1040017e6e3ae6c8a48c97704dbfde7bd0dbc186af534e1bbc654';
let bytesArray = []
for (let i = 0, len = data.length; i < len; i = i + 4) {
bytesArray.push(parseInt(data[i] + data[i + 1]+data[i+2]+data[i+3], 16));
}
let buffer = new Uint16Array(bytesArray)
这样写不用设置TypeArray的大小了,很方便,事实上这个buffer是646字节。
关于为什么用UintArray16储存时每两个字节会颠倒顺序可以参考这几篇文章
搞懂 ArrayBuffer、TypedArray、DataView 的对比和使用
详解-定型数组-DataView-ArrayBuffer
什么是大端小端 and 如何判断大端小端
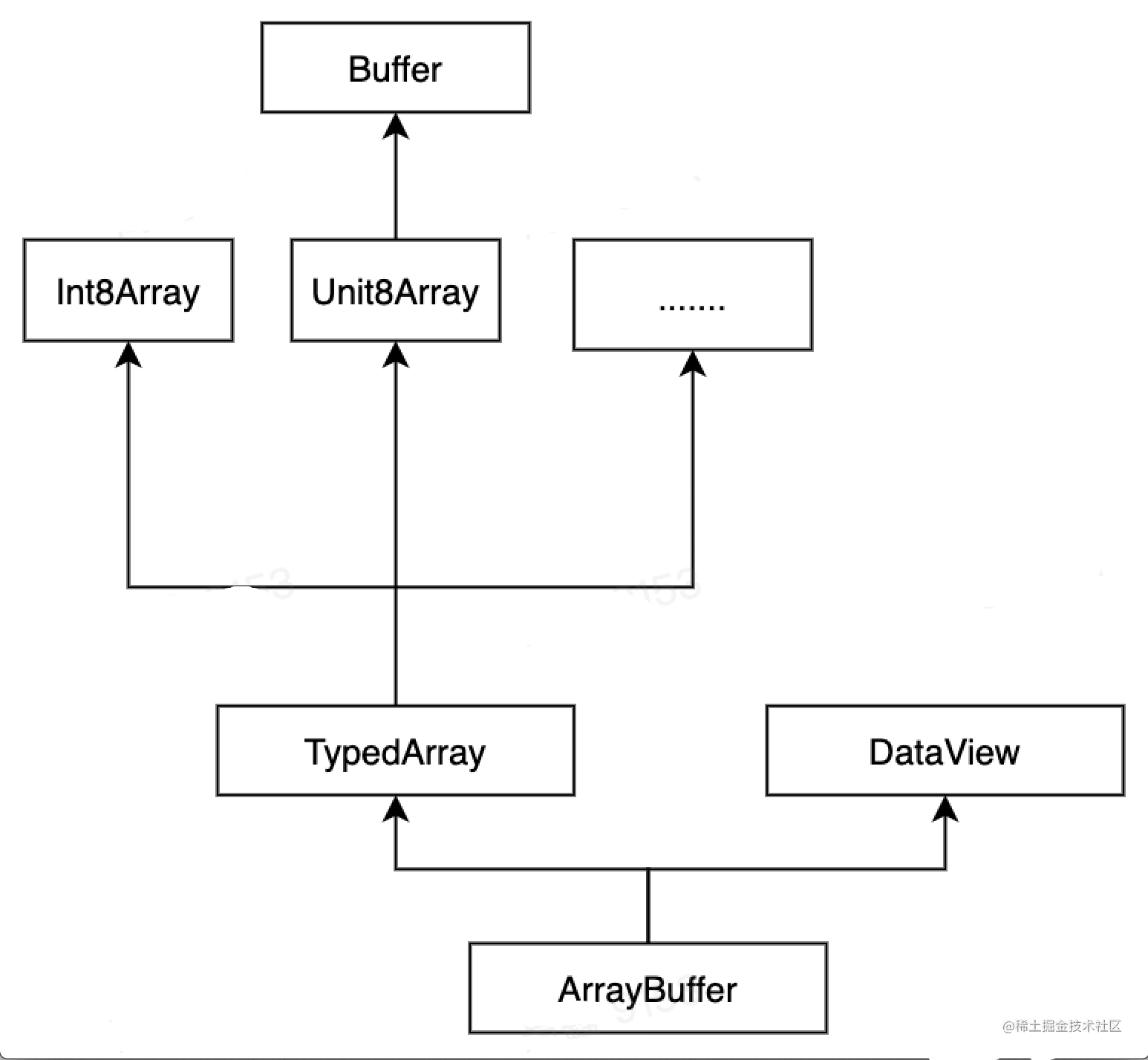
原因是操作系统存储数据时的大小端模式,总结是用TypedArray构造的buffer不能设置大小端,且根据操作系统来定,即一个16进制19f1存储成小端就是f119,用DataView构造的buffer可以设置大小端,且默认是大端。TCP/IP协议规定传输的数据必须是大端。
为什么存在 大端 模式 小端
为什么会有大小端模式之分呢?
比如一个16进制19f1,19是高字节,f1是低字节,放到内存0x0010中,如果是小端模式,将f1放到低内存位,即0x0010,将19放到高内存位,即0x0010往后移一个字节,即0x0011,大端相反。
小端模式优点:
内存的低地址处存放低字节,所以在强制转换数据时不需要调整字节的内容(注解:比如把int的4字节强制转换成short的2字节时,就直接把int数据存储的前两个字节给short就行,因为其前两个字节刚好就是最低的两个字节,符合转换逻辑);
CPU做数值运算时从内存中依顺序依次从低位到高位取数据进行运算,直到最后刷新最高位的符号位,这样的运算方式会更高效。
大端模式优点:
符号位在所表示的数据的内存的第一个字节中,便于快速判断数据的正负和大小。
其各自的优点就是对方的缺点,正因为两者彼此不分伯仲,再加上一些硬件厂商的坚持,因此在多字节存储顺序上始终没有一个统一的标准。
16进制每两位就是1字节,0b11111111==0xff,这样得来。
再次感谢冷山哥哥🙂。(首尾呼应了)










 置顶卡
置顶卡 沉默卡
沉默卡 照妖镜
照妖镜






