首先我们直接写一个简单的脱离页面的开始刷课按钮
let btn=document.createElement("div");
btn.innerHTML='<button style="position: fixed;bottom: 80vw;right: 0;z-index: 99;height: 50px;">开始刷课</button>';
btn.onclick=function(){
//code
alert("点击了按钮");
}
document.body.append(btn);
一旦点击就开始搜索元素
效果如下
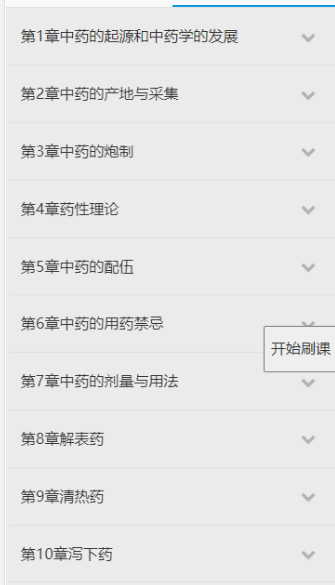
接下来开始写分析页面尝试写出自动点击工具
一旦点击章节会post读取对应的章节属性
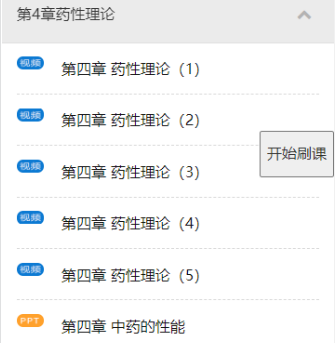
如果点击某些章节,还会出现子章节,并且也会post读取章节属性
所以我们可以总结出两点
1.章节存在视频
2.章节存在子章节
3.即使存在子章节也有可能存在视频
如果我们摊开dom元素看
就可以发现noContent是只存在视频的,而不存在noContent的是存在子章节的
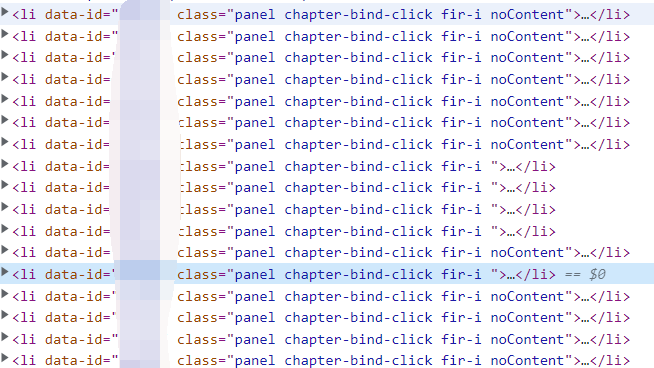
我们再观察有章节的,也就是不存在noContent的class元素的属性
可以发现,内部直接显示了子章节

那么我们的逻辑就非常明确了
1.获取noContent的章节
2.获取没有noContent的父章节
3.获取没有noContent的父章节的子章节
把三个章节都给合并到一个数组里
理论建立完毕,开始实战
document.querySelectorAll(".shareResources > .panel-group > li")
男人就要猛一点,我们直接获取所有第一级的章节
然后获取不为noContent的class元素,遍历读取子章节
我们使用not反选符获取到所有没有noContent的class类的元素

然后我们可以再在其元素上再调用querySelector,这个时候可以使用foreach循环
因为这部分比较简单
所以直接上代码
ChapterList=ChapterList.concat(...document.querySelectorAll(".shareResources > .panel-group > li"))
let ParentChapert= document.querySelectorAll(".shareResources > .panel-group > li:not(.noContent)")
ParentChapert.forEach((item) => {
ChapterList=ChapterList.concat(...item.querySelectorAll(".chapter-content [data-secid]"))
});
console.log('ChapterList',ChapterList)

可以看到拿到了所有章节元素加子元素!
那么我们这节课就结束了
结语
撒花~











 置顶卡
置顶卡 沉默卡
沉默卡 照妖镜
照妖镜