调试发现用了canny反而不好,直接跑findContours可以识别出来全部内容

我们可以利用面积进行过滤
复合面积的方块取左上和右下进行ocr
先取点画出来看看
for i in range(len(contours)):
area = cv2.contourArea(contours[i])
if area > 500:
x, y, w, h = cv2.boundingRect(contours[i])
top_left = (x, y)
bottom_right = (x + w, y + h)
cv2.rectangle(originImage, top_left, bottom_right, (0, 0, 255), 2)
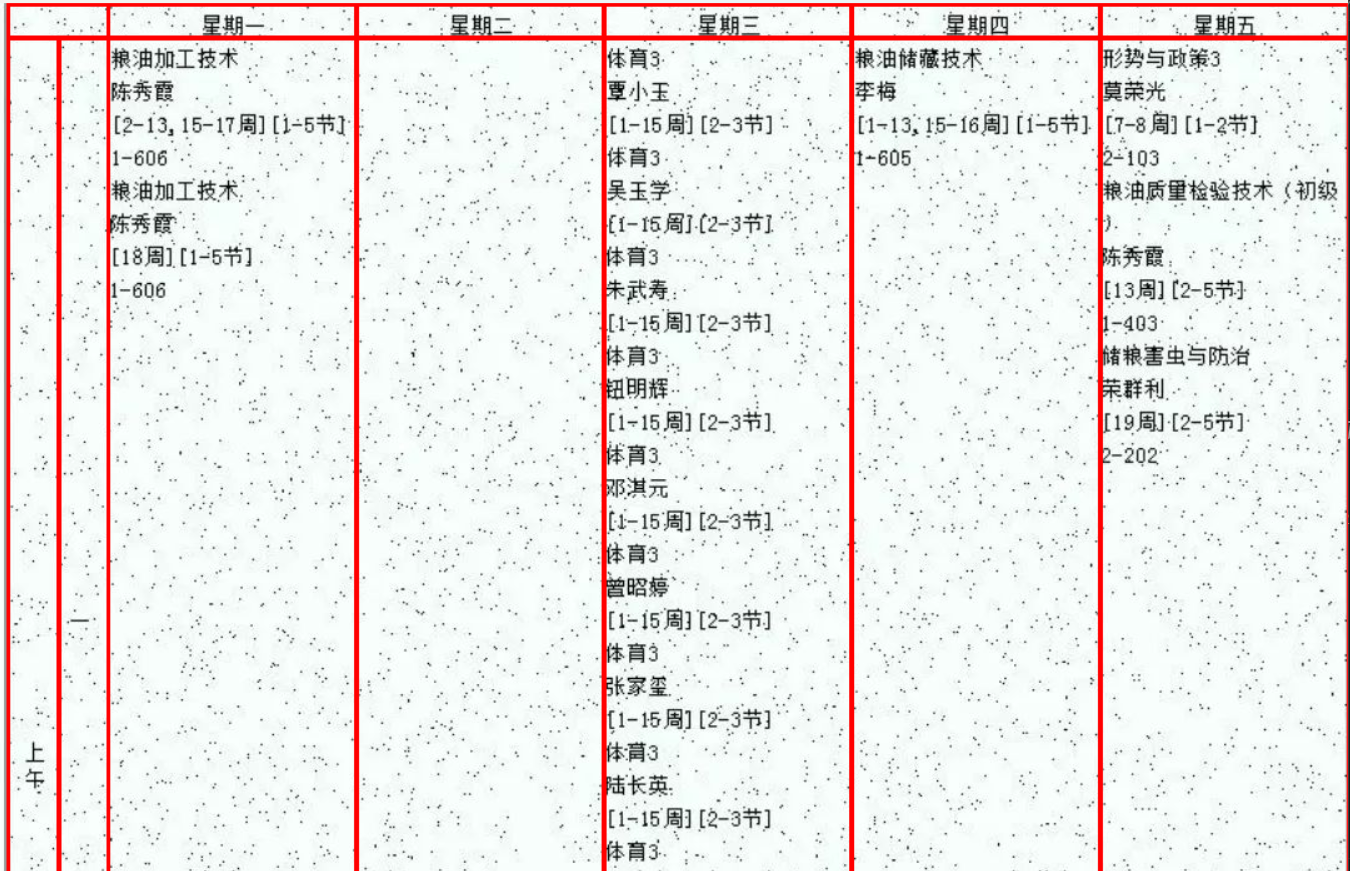
然后就是跑ocr的问题了
根据测试pytesseract 的效果并不是特别好
反而百度的paddle识别效果还不错
https://paddlepaddle.github.io/PaddleOCR/latest/ppocr/visualization.html#_3
直接初始化一下
from paddleocr import PaddleOCR
logging.disable(logging.DEBUG)
ocr = PaddleOCR(use_angle_cls=True, lang='ch')
然后在获取方块的时候得到ori图片进行ocr识别
text = ""
for line in result:
if line is not None:
for word_info in line:
text += word_info[1][0]
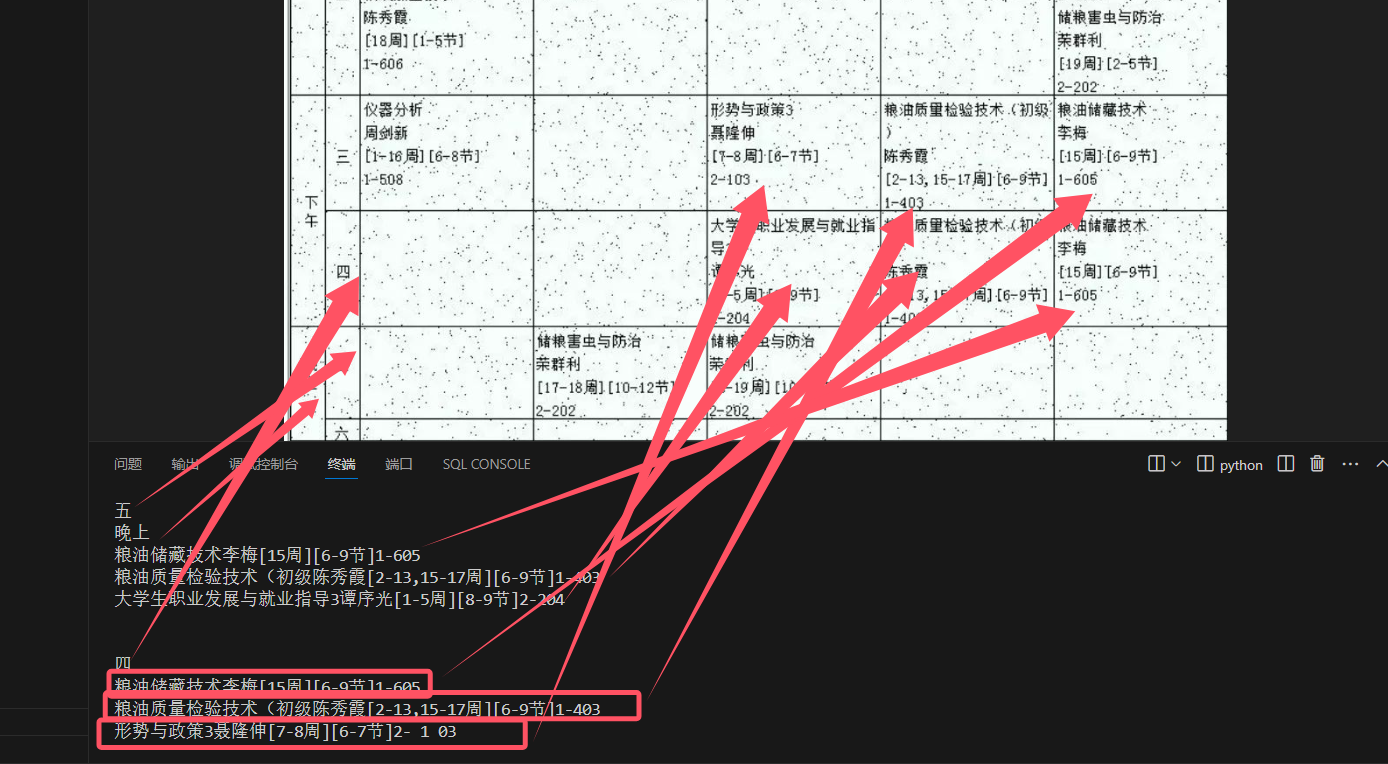
可以发现图片内的内容都能一一对上
既有坐标又有文字
剩下的只是编码部分了
有心情再写吧
缅怀小米课程表
实际小米的处理肯定比我操作的更为复杂
一通操作下来只是怀念
既是怀念曾经的小米,也是纪念那个还热泪盈眶又笨笨的自己











 置顶卡
置顶卡 沉默卡
沉默卡 照妖镜
照妖镜
