签到天数: 9 天
[LV.3]偶尔看看II
200
2
538
专家
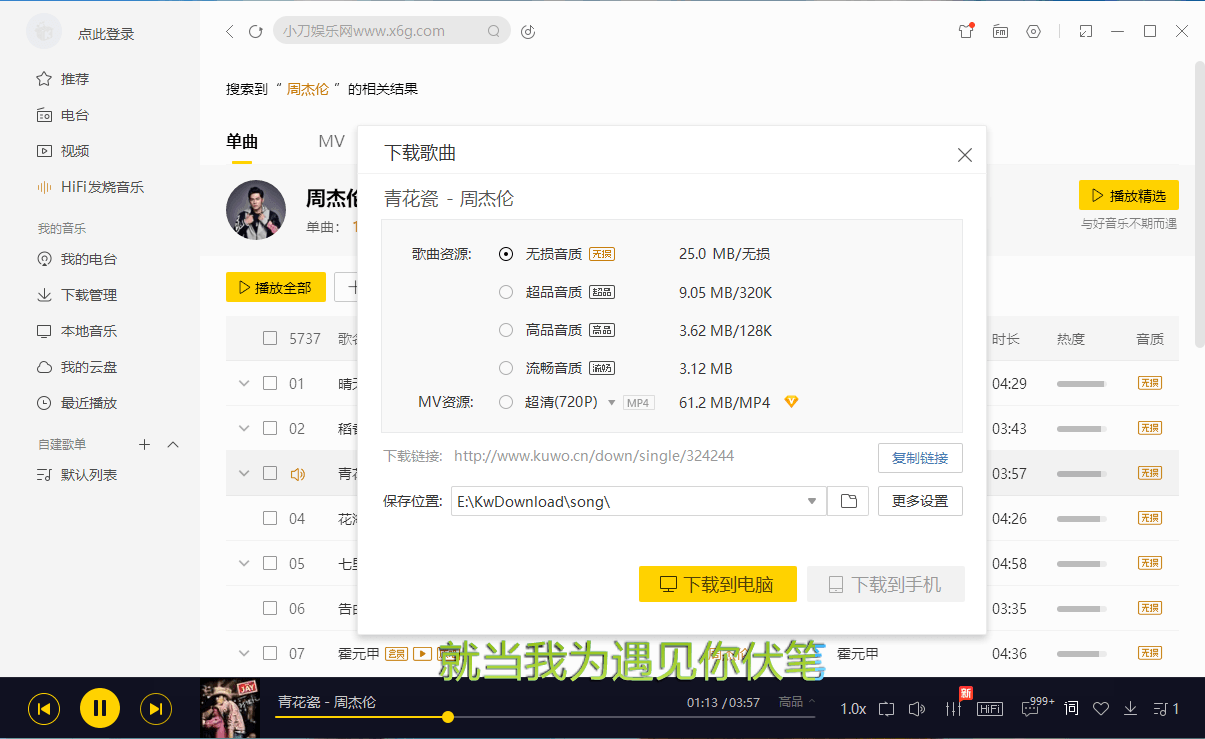
近年来随着版权意识的加强,好多音乐软件客户端在应对反和谐方面越来越严,如今也只有酷我音乐客户端在这方面仍存在BUG,让大家有机可乘,免费下载付费歌曲、无损音乐,不花钱真香。
我用夸克网盘分享了「KW音乐PC版_--9.2.0.0_W6_去广告破解豪华-IP-色版.7z」,点击链接即可保存。打开「夸克APP」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。链接:https://pan.quark.cn/s/76f2d49ad7dd
使用道具 举报
该用户从未签到
0
8
5
助理工程师
签到天数: 1 天
[LV.1]初来乍到
20
13
签到天数: 6 天
[LV.2]偶尔看看I
24
15
4
本版积分规则 发表回复







 置顶卡
置顶卡 沉默卡
沉默卡 照妖镜
照妖镜
