本帖最后由 hysaoh 于 2022-7-18 17:30 编辑
本帖最后由 hysaoh 于 2022-7-18 17:13 编辑
本帖最后由 hysaoh 于 2022-7-18 17:05 编辑
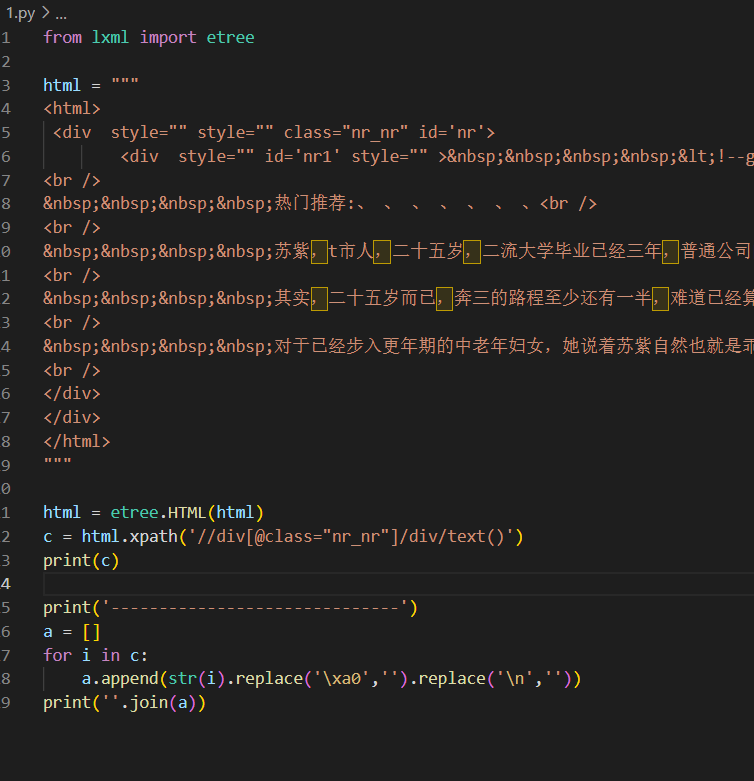
请考虑使用python的BeautifulSoup库,对网页进行解析。
获取到soup,使用.text方法p即可获得文本。虽然在Pycharm中可以看到NBSP但是记事本看空格,可以直接保存
例如soup.text。
下面是我对一个小说网站书架的爬取,可以参考一下。
小说网址为https://www.bswtan.com/
账号,密码因为隐私原因已经略去。
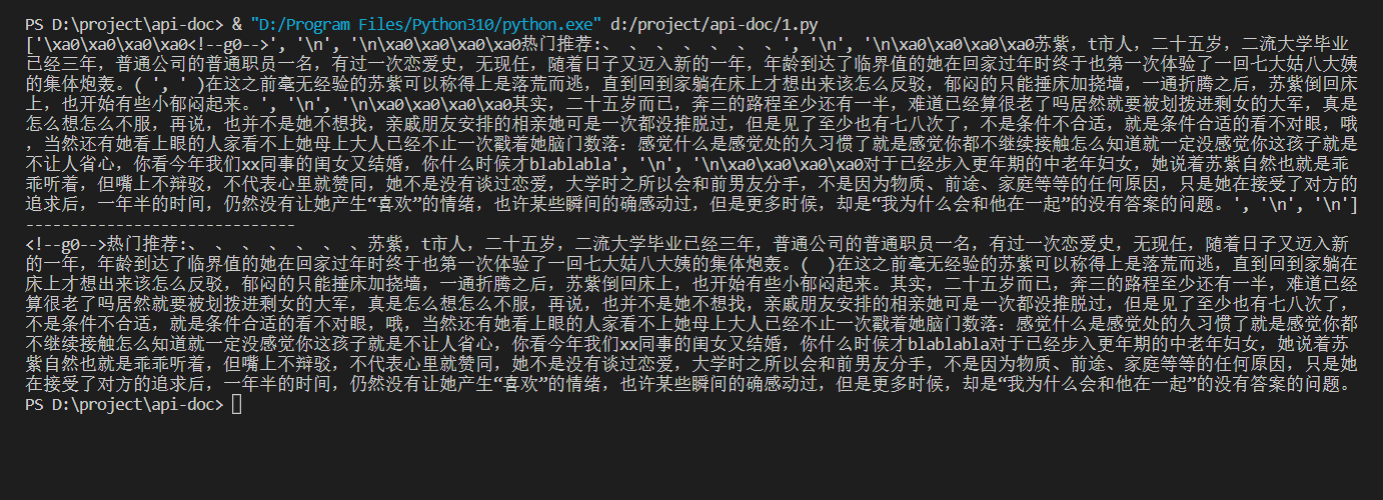
# -*- coding: utf-8 -*-
"""
@Author :Cat
@Date : 2022年 05月 16日
@Introduction :A Lazy Cat
"""
import re
import time
import requests
from bs4 import BeautifulSoup
def can_read(uri):
sss = session.get("https://www.bswtan.com/%s" % uri,timeout=3, proxies=proxies)
sss.encoding = "UTF-8"
soup = BeautifulSoup(sss.text, "html.parser")
soup_select = soup.select("#content")
# 小说长度
len1 = len(re.sub(r'<.*?>| ', '', str(soup_select)))
if len1 > 2000:
return True
else:
return False
if __name__ == '__main__':
url = "https://www.bswtan.com/login.php"
username = "用户名已经替换"
password = "密码已经替换"
payload = 'LoginForm%5Busername%5D={0}&LoginForm%5Bpassword%5D={1}'.format(username, password)
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
}
#设置代理,如果不需要代理就删掉下面这一行,并查找替换掉proxies=proxies。
proxies = {
'https': 'SOCKS5://127.0.0.1:7890'}
session = requests.session()
session.post(url, headers=headers, data=payload, timeout=10, proxies=proxies)
get = session.get("https://www.bswtan.com/modules/article/bookcase.php", timeout=3, proxies=proxies)
get.encoding = "utf-8"
print(get.text)
soup = BeautifulSoup(get.text, "html.parser")
select = soup.select('.grid')[0].select('tr td >a')
book_name = select[0::2]
up = soup.select('.grid')[0].select('tr td span>a')
book = list(map(lambda x: x.string, book_name))
up = list(map(lambda x: (x.get("href"), x.string), up))
a = up[0::2]
b = up[1::2]
is_update = []
booklist = {}
read = can_read(a[1][0])
for i in range(len(a)):
booklist[book[i]] = [a[i][1], b[i][1], (not a[i] == b[i]), ["否", "是"][can_read(a[i][0])]]
for (k, v) in booklist.items():
if v[2]:
print("《%s》有更新!\n\t最新章节为:%s\t是否可读?:%s\n\t阅读进度为:%s" % (k, v[0], v[3], v[1]))









 置顶卡
置顶卡 沉默卡
沉默卡 照妖镜
照妖镜











 道道永远是我男神!!!!!
道道永远是我男神!!!!!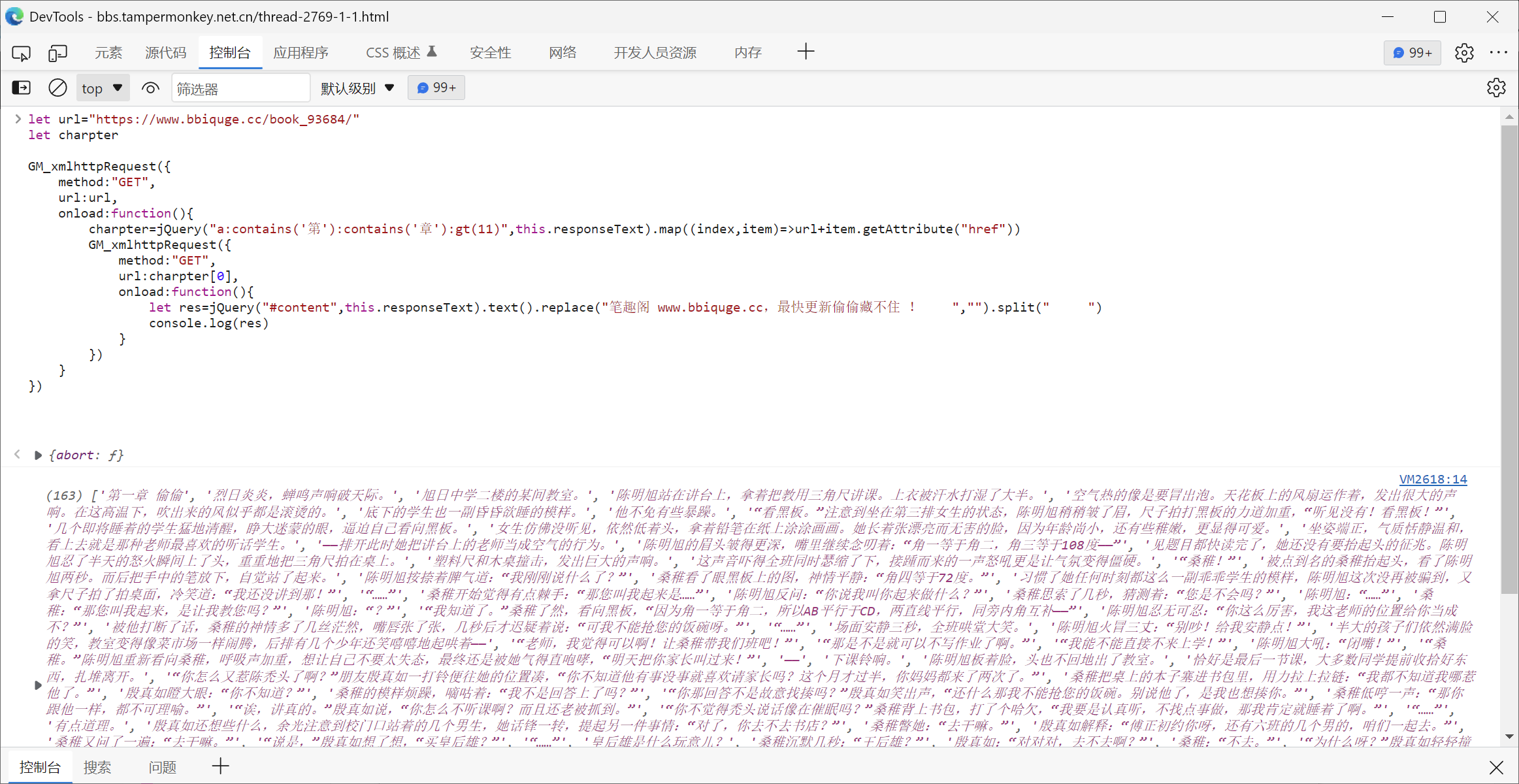
 谢谢了老哥!我受到了启发 栓q!!
谢谢了老哥!我受到了启发 栓q!!