

|
发表于
2024-3-23 05:07:56
|
显示全部楼层
| ||
|
混的人。
------------------------------------------ 進撃!永遠の帝国の破壊虎---李恒道 入驻了爱发电https://afdian.com/a/lihengdao666 |
||
|
发表于
2024-3-23 10:22:58
|
显示全部楼层
| ||
|
上不慕古,下不肖俗。为疏为懒,不敢为狂。为拙为愚,不敢为恶。
|
||
|
发表于
2024-3-24 05:46:48
|
显示全部楼层
| ||
|
混的人。
------------------------------------------ 進撃!永遠の帝国の破壊虎---李恒道 入驻了爱发电https://afdian.com/a/lihengdao666 |
||
|
发表于
2024-3-24 13:04:46
|
显示全部楼层
| ||
|
上不慕古,下不肖俗。为疏为懒,不敢为狂。为拙为愚,不敢为恶。
|
||
|
发表于
2024-3-24 13:52:55
|
显示全部楼层
| ||
|
发表于
2024-3-24 22:54:23
|
显示全部楼层
| ||
|
混的人。
------------------------------------------ 進撃!永遠の帝国の破壊虎---李恒道 入驻了爱发电https://afdian.com/a/lihengdao666 |
||









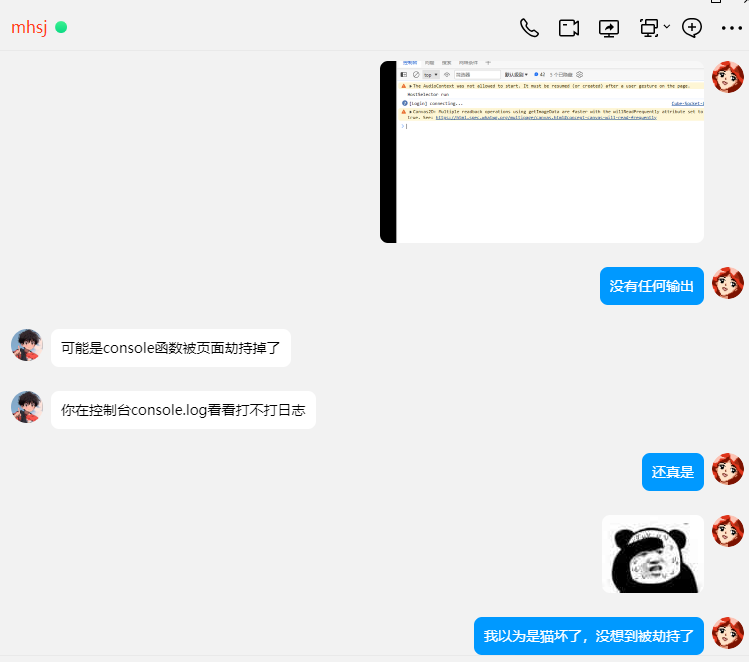
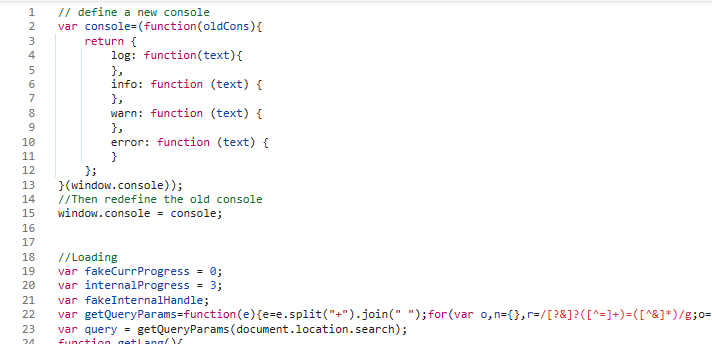





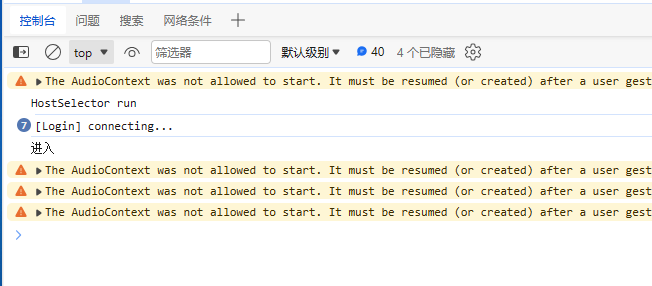
 置顶卡
置顶卡 沉默卡
沉默卡 照妖镜
照妖镜







