本帖最后由 tfsn20 于 2024-2-11 21:10 编辑
起因
起因是我想使用nltk库对文献进行词性分析,但发现解析文献时对于符号比较混乱,html相比PDF好一点,但会有一些上下角标和latex的符号被识别为另外一段的开始,比如这样:
原图片

WORD图片
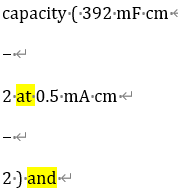
这些符号通常是非ascii字符,导致使用docx-py库解析时出现这样的情况。另外html排版中文字连接符有时居然也会用上表的负数符号表示(混淆???)
解决
常见文献格式有PDF,但在解析文本内容时会出现乱码的情况(特别是一些符号和公式),因此本脚本直接在文献原站上解析html,更容易解析符号和公式。
文献网站格式化导出txt, html, doc, docx,docx导出借助docx.js库实现;
打开网站后,页面上方出现闪烁按钮,按下即可导出txt, html, doc, docx文件到浏览器下载目录;
移除图片,引注,引用,公式的一部分(如分号和根号)
目前支持sciencedirect网站,移除了图片,保留图注;移除了图片下载文字和引用序号,导出文献的标题|摘要|关键词|主题内容使用换行符隔开, 对上标下标以及公式没有进行上下标解析,仅仅对上标做了替换,因此导出的docx中是无格式的;有需要的小伙伴可以借助https://cdn.jsdelivr.net/npm/[email protected]/build/index.umd.min.js库实现;
支持rsc网站(移除作者相关和于Conflicts of interest后与论文主题无关的东西)。
支持springer站。
后面可能会支持上下标解析和公式解析,也会支持其他网站。
公式对比
原图片

WORD图片

更新说明
由于我是对文献摘要和主题内容进行词性分析,所以后续脚本更新可能不会对公式,角标等符号进行解析支持,看看再说吧。
0.2.0增加了自定义配置项,默认不保留图注(可通过配置更改),替换\u223c ∼为~,替换img alt 'radical dot'为\u2022 •;由于nltk库的sent_tokenize会把标题和小标题中的句点符号当作句子结束,因此还增加了是否将其转换为一点前导符的选项。










 置顶卡
置顶卡 沉默卡
沉默卡 照妖镜
照妖镜





